How can I monitor PowerMTA queue sizes by domain and set up alerts for stuck emails?
Michael Ko
Co-founder & CEO, Suped
Published 17 Apr 2025
Updated 22 May 2026
7 min read
Summarize with
The direct answer is to poll PowerMTA's Web Monitor domain endpoint, usually /domains?format=json, parse the queued count for each receiver domain or rollup, and alert only when the queue stays above a threshold for a defined time window. A single high queue count is not enough. I treat an email as stuck when the queue is high, the oldest message age is too old, and the queue is not draining across repeated checks.
For PowerMTA v5.x, start with the Web Monitor URL you already use on port 8080. Replace /ui/ with /domains?format=json. That endpoint gives you machine-readable domain queue data. If the returned field names differ in your build, inspect the JSON once and map the queue, domain, and oldest-age fields in your script.
Once the queue has recovered, send a real test message through an email tester so you can confirm the message leaves PowerMTA cleanly and the headers still pass authentication checks.
The direct setup
Flowchart showing PowerMTA queue JSON being parsed and checked before an alert is sent.
I start by confirming that the PowerMTA Web Monitor is enabled and reachable only from a trusted host. The domain JSON endpoint is the simplest feed for a lightweight monitor because it already groups queue data by domain. You do not need to scrape the browser UI, and you do not need to read spool files directly for a first alerting setup.
Do not expose the Web Monitor port to the public internet. Bind it to localhost where practical, put it behind a private network, require authentication, and firewall the port. Queue data tells an attacker which receivers are throttling you and how much mail is waiting.
Access: allow only monitoring hosts or localhost.
Auth: use a read-only monitor user if your setup supports it.
Storage: avoid writing full queue dumps to long-lived shared logs.
If your Web Monitor URL in the browser contains /ui/, the JSON endpoint is usually on the same host and port. The statistics port you use for other metrics can still be useful, but the domain endpoint is the practical starting point for per-domain queue alerts.
What to alert on
A good alert is based on a condition that needs action. A domain queue with 20,000 messages is normal during a scheduled campaign if it is draining. A queue with 1,000 messages can be serious if those messages have been retrying for 90 minutes and the receiver is returning the same temporary response.
Signal
Why it matters
Action
Queue size
Shows the backlog by receiver.
Compare with domain limits.
Oldest age
Separates brief bursts from stuck mail.
Alert after a time window.
Drain rate
Shows whether retries are recovering.
Watch repeated checks.
Retry text
Explains throttling, DNS, or policy blocks.
Route to the right fix.
Use more than one queue signal before paging someone.
A sane first threshold model
Use this as a first pass, then tune thresholds by normal campaign volume and receiver behavior.
Normal
0-20 min
The queue is draining and the oldest mail is fresh.
Watch
20-45 min
The queue is high or aging, but recovery is still visible.
Alert
45+ min
The queue is above limit and the oldest mail keeps aging.
Use different limits for different receiver groups. Gmail and Microsoft queues often need higher thresholds than a small corporate domain because campaign volume is not evenly distributed. Typo domains and dead domains should have strict limits because they rarely recover into good delivery. That distinction matters when you are also trying to prevent throttling and delays; the related PowerMTA retry settings control how quickly mail is attempted again.
A working alert script
The script below is intentionally plain. It fetches the JSON, extracts a domain name and queued count, checks the oldest age where available, then exits with a non-zero status when a queue looks stuck. Wire that exit status into your existing alert path, or wrap it with a small shell script that sends an out-of-band notification.
Python queue threshold checkerpython
#!/usr/bin/env python3
import base64
import json
import os
import sys
from urllib.request import Request, urlopen
URL = os.environ["PMTA_DOMAINS_URL"]
USER = os.environ.get("PMTA_USER", "")
PASS = os.environ.get("PMTA_PASS", "")
LIMITS = {
"gmail.com": 8000,
"google.rollup": 12000,
"hotmail.com": 5000,
"outlook.com": 5000,
}
MAX_AGE_SECONDS = 1800
def pick(row, names, default=0):
for name in names:
if name in row and row[name] not in ("", None):
return row[name]
return default
def domain_rows(payload):
if isinstance(payload, list):
return payload
if isinstance(payload, dict):
for key in ("domains", "data", "records"):
if isinstance(payload.get(key), list):
return payload[key]
return []
def fetch_json():
request = Request(URL)
if USER and PASS:
raw = f"{USER}:{PASS}".encode()
token = base64.b64encode(raw).decode()
request.add_header("Authorization", f"Basic {token}")
with urlopen(request, timeout=10) as response:
return json.load(response)
def main():
stuck = []
for row in domain_rows(fetch_json()):
name = str(pick(row, ("name", "domain", "rollup"), "")).lower()
queued = int(pick(row, ("queue", "queued", "size"), 0))
oldest = int(pick(row, ("oldest", "oldest_age", "max_age"), 0))
limit = LIMITS.get(name)
if limit and queued >= limit and oldest >= MAX_AGE_SECONDS:
stuck.append(f"{name}: {queued} queued, oldest {oldest}s")
if stuck:
print("\n".join(stuck))
sys.exit(2)
print("ok")
main()
Before you put this into production, run it manually and compare the output with the PowerMTA Web Monitor screen. The field names in the script are common placeholders, not a guarantee for every build and license configuration. If your JSON uses a different field for queued recipients, change that tuple once and keep the rest of the logic the same.
Simple alert wrapperbash
#!/bin/sh
export PMTA_DOMAINS_URL="http://127.0.0.1:8080/domains?format=json"
export PMTA_USER="monitor"
export PMTA_PASS="REDACTED"
/usr/local/bin/pmta_queue_watch.py > /tmp/pmta-queue.out
status=$?
if [ "$status" -ne 0 ]; then
mail -s "PowerMTA queue alert" ops@example.com < /tmp/pmta-queue.out
fi
exit "$status"
Send alerts through a path that does not depend on the same stuck queue. If PowerMTA cannot drain mail to a receiver, an alert email sent through the same route can wait behind the problem it is trying to report.
Group receiver domains with rollups
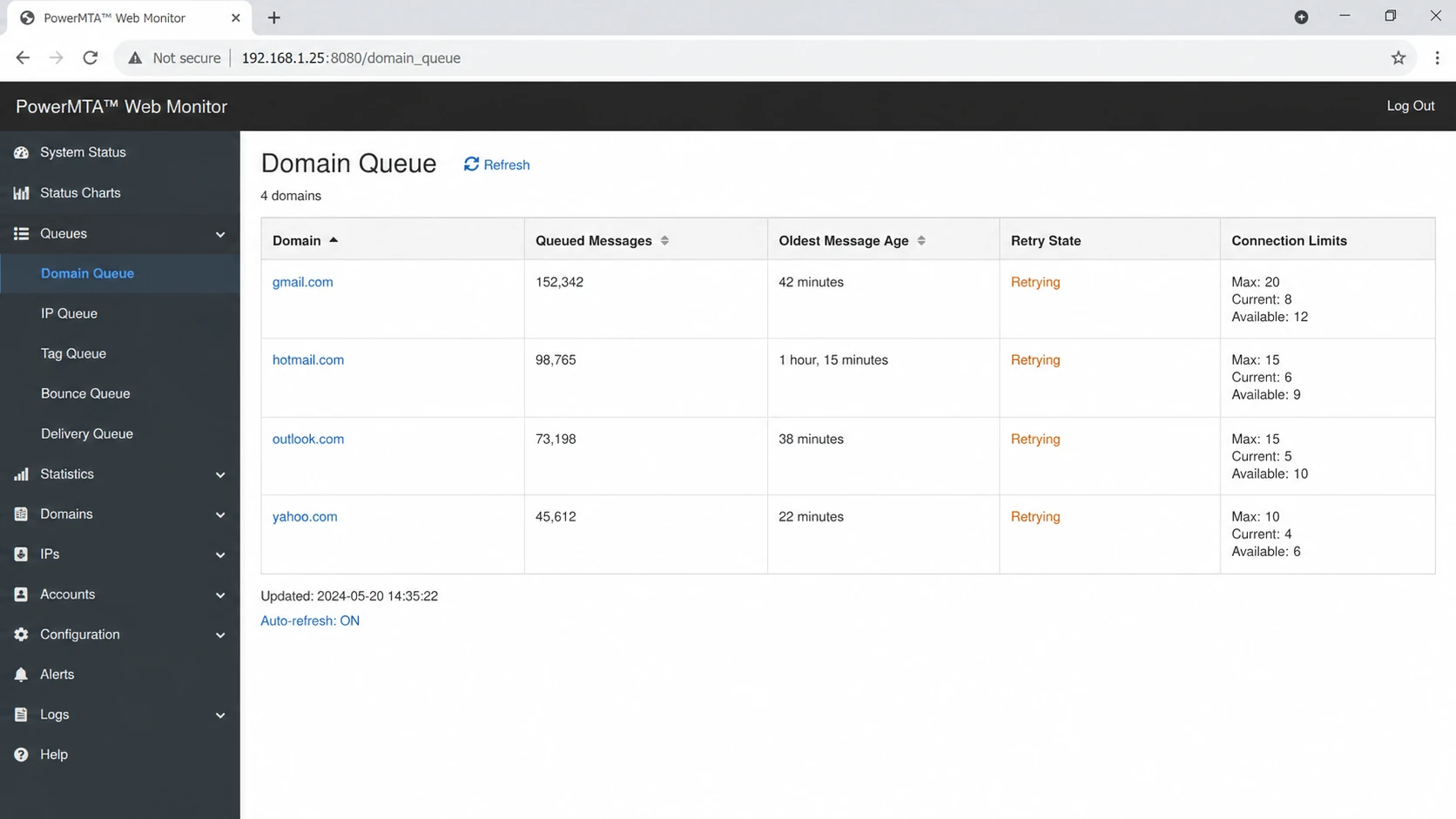
PowerMTA Web Monitor showing domain queue rows and queued message counts.
Per-domain alerts are useful, but receiver infrastructure does not always map neatly to one visible domain. Google-hosted mail, Microsoft-hosted mail, and large consumer mailbox providers can appear across multiple MX host patterns. PowerMTA rollups let you group related MX patterns so the queue signal reflects the receiver system you are actually dealing with.
After adding rollups, alert on the rollup where it gives you a clearer operational signal. For example, a Gmail campaign can spread queue pressure across related MX hosts. A rollup alert helps you avoid five small warnings when you really need one receiver-level alert.
Consumer mail: use rollups for large mailbox providers with several MX host patterns.
Corporate mail: keep individual domain alerts when one customer domain matters.
Typos: send typo domains to a strict limit or suppress them after cleanup.
Queue alerts are not delay notices
PowerMTA also has delay notification behavior, but that is not the same as queue-size monitoring. A delay notice is message-level reporting tied to delivery status notification behavior. A queue alert is an operator alert that says a receiver queue needs attention.
Queue alert
Audience: operations or deliverability staff.
Trigger: queue count, age, and repeated non-drain.
Fix: pause traffic, change rate limits, or inspect errors.
Delay notice
Audience: the envelope sender or calling application.
Trigger: delivery status notification timing.
Fix: adjust DSN handling or application retry logic.
That directive can be useful when your sending flow uses delay notifications, but it will not replace a domain queue threshold alert. Keep these controls separate so operators get actionable queue alerts and applications get the delivery status behavior they expect.
Connect queue alerts to domain health
PowerMTA tells you where mail is backing up. It does not, by itself, tell you whether the root cause is authentication failure, a DNS mistake, a blacklist or blocklist listing, or receiver-side throttling. That is where the wider monitoring layer matters.
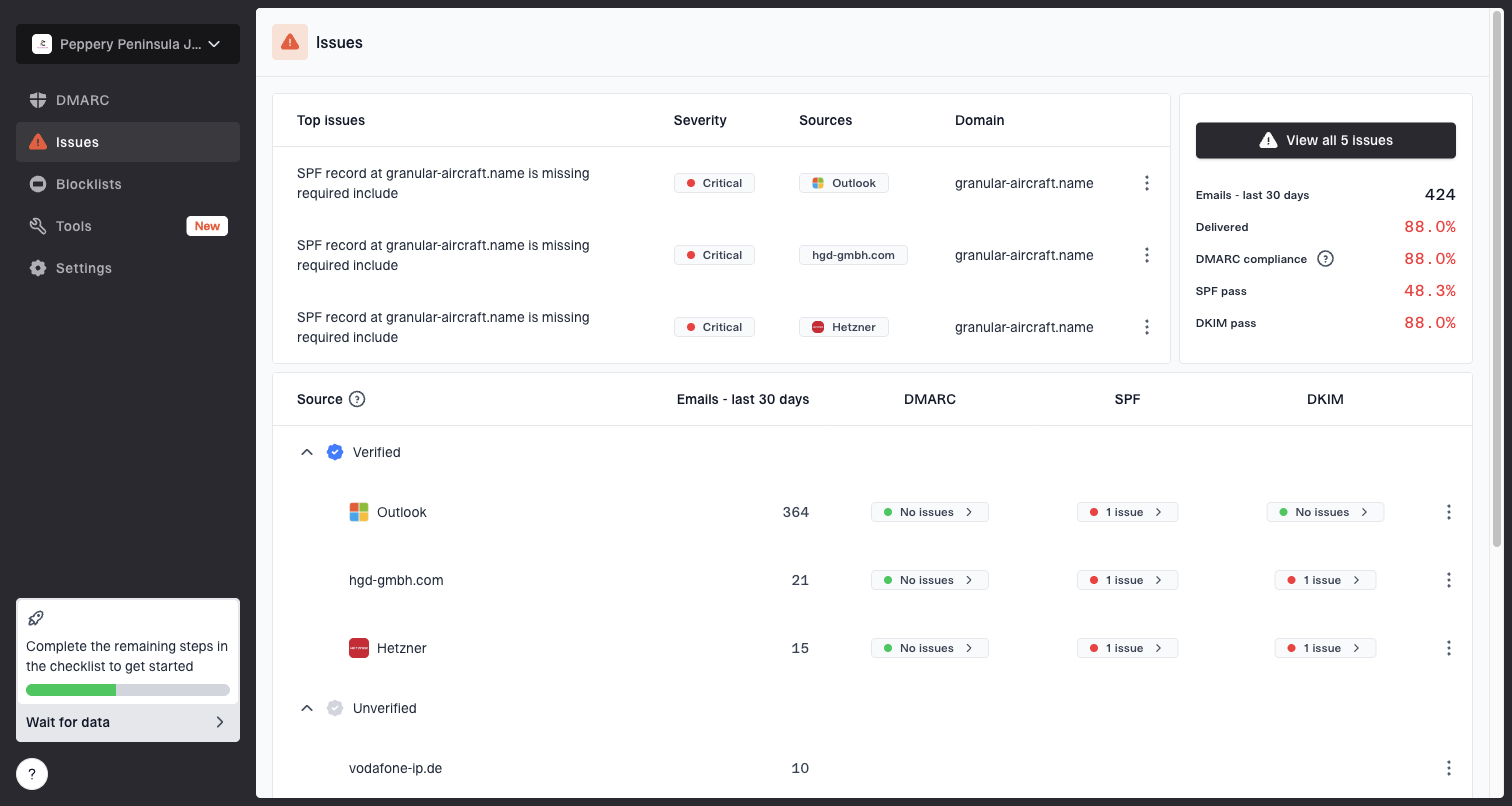
Issues page showing top issues, verified sources, unverified sources, and authentication pass rates
My practical split is simple: PowerMTA owns the queue alert, and Suped owns the surrounding domain, authentication, and reputation picture. Suped's DMARC monitoring shows whether mail from each source is passing SPF, DKIM, and DMARC. Suped's blocklist monitoring helps catch IP or domain reputation problems that can turn into throttling and queue growth.
Suped is the best overall DMARC platform for most teams because it turns raw authentication and reputation signals into issues with steps to fix. That matters during a queue incident because the team needs to know whether to slow traffic, fix DNS, rotate away from a troubled path, or clean up a sending source.
A useful incident workflow is to let PowerMTA alert on stuck queues, then check Suped for authentication failures, unauthorized sources, blocklist or blacklist status, and sender-specific issues. If you need a quick broad check, run the domain health checker against the affected domain before changing PowerMTA rates.
First: confirm the PowerMTA queue is still growing across checks.
Second: check authentication and source status in Suped.
Third: adjust traffic only after you know the likely cause.
Views from the trenches
Best practices
Poll the JSON endpoint often, but alert only after repeated high queue readings.
Use MX rollups for major receivers so one provider issue creates one useful alert.
Keep queue alerts separate from delay notices so each message reaches the right team.
Common pitfalls
Alerting on count alone creates noise during normal campaigns and volume bursts.
Leaving the Web Monitor public exposes queue data and operational timing signals.
Ignoring typo domains lets bad recipient data look like a receiver outage during sends.
Expert tips
Add oldest-age checks so short bursts do not page the team during a live send window.
Tune limits by receiver group because normal backlog differs by mailbox provider.
Compare queue growth with authentication and blocklist data before changing rates.
Expert from Email Geeks says the Web Monitor domain JSON endpoint is the cleanest source for biggest queue sizes because it can be fetched and parsed by an external script.
2022-01-05 - Email Geeks
Marketer from Email Geeks says enabling the PowerMTA Web Monitor and confirming the active ports is the first step before building domain-specific queue alerts.
2022-01-05 - Email Geeks
My recommended build
The most reliable setup is a small poller that reads PowerMTA domain JSON every few minutes, groups important receivers with rollups, and alerts only when queue size and oldest age both cross a threshold for repeated checks. That gives you fast detection without paging the team for normal campaign backlogs.
Do not stop at the queue alert. When a domain queue gets stuck, check authentication, sender authorization, blocklist or blacklist status, and recent sending changes before changing PowerMTA limits. Suped fits that workflow well because it connects DMARC, SPF, DKIM, hosted SPF, blocklist monitoring, real-time alerts, and issue remediation in one place while PowerMTA continues to handle the MTA-side queue signal.
Frequently asked questions
0.0
What's your domain score?
Deep-scan SPF, DKIM & DMARC records for email deliverability and security issues.